Papyri: Agentic Document Flows
Establish governed, zero-touch document pipelines that ensure consistent interpretation, transformation, and archival across mission-critical business processes.
Drag and Drop Configurable Automation Nodes
Create powerful automation with modular nodes, intuitive branching, and reliable processing without needing engineering expertise.
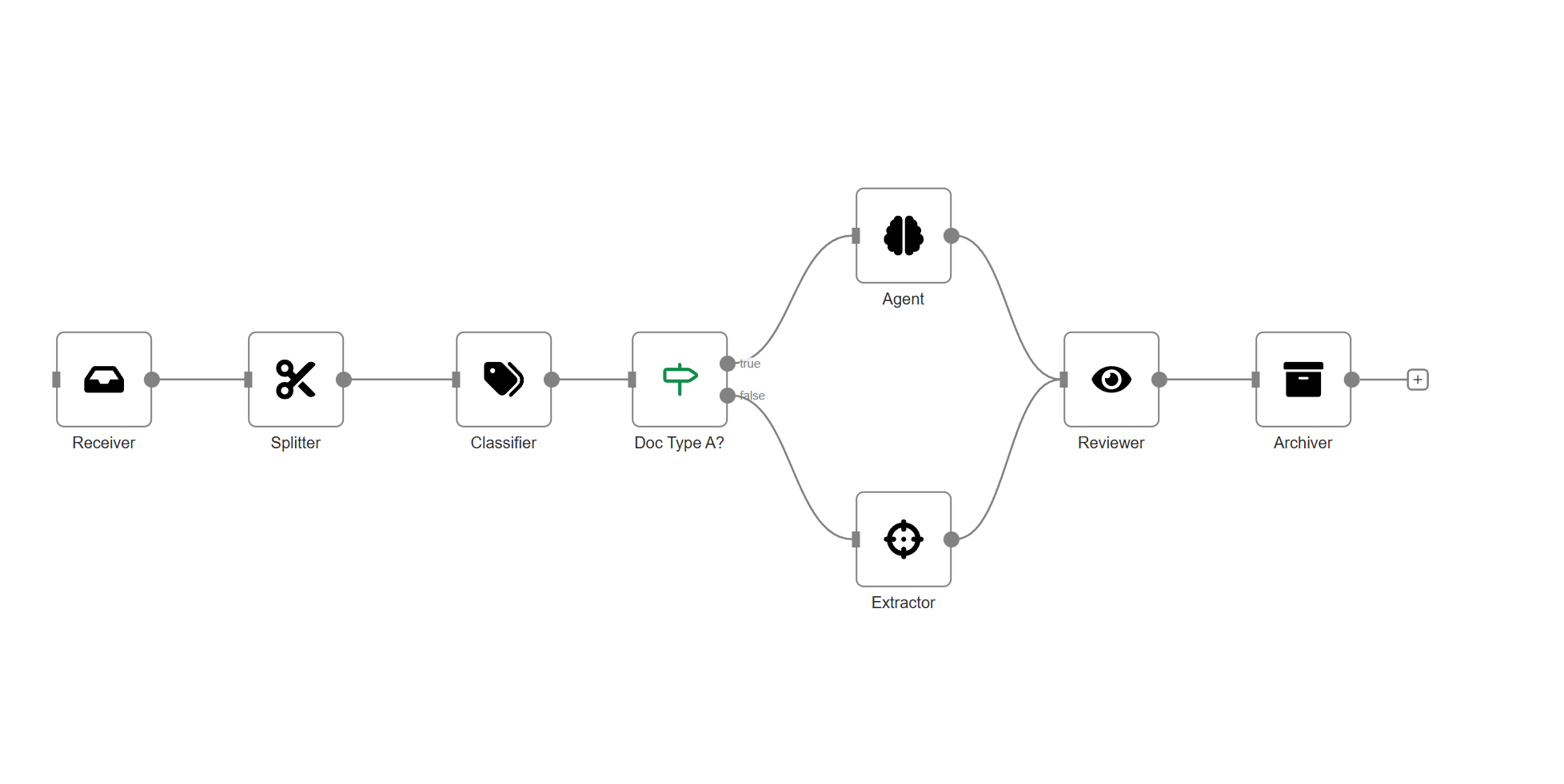
Specialized Nodes for Every Document Task
Reader
Convert documents into AI-Ready Digital Twins.
- Recognizes layout & structure
- Visual confidence overlays
- Processes any format
Enhancer
Restore and optimize degraded document images.
- Cleans scanning artifacts
- Discards empty pages
- Reconstructs illegible text
Agent
Execute complex cognitive tasks with AI.
- Grounded Outputs driven form documents.
- Tool Execution
- Multi-Doc Reasoning
- Guard Rails
Splitter
Organize mixed batches into structured documents.
- Intelligent Logic: Content-aware boundaries
- Landmark or Field based Splitting
- Learns your splitting rules
Assembler
Gather documents into complete business cases.
- Auto Collation: Groups related documents
- Continuous Update: Adds new files instantly
- Checklist Guided: Validates against requirements
Classifier
Categorize documents using business-aware taxonomies.
- Dynamic Taxonomy: Tracks evolving categories
- Confidence Check: Thresholds trigger review
- Decision Maker: Teach it to make decision on your documents
Extractor
Capture structured data from unstructured documents.
- Extracts with precision
- Entity Linking: Associates data to owners
- Built-in Validation: Cross-checks extracted values
Redactor
Mask sensitive data with semantic precision.
- Role Based: Controls visibility by user
- Flexible Modes: View-only or permanent
- Synthetic Data: Replaces sensitive info
AI Coach
Train specialized models on your data.
- Learns from your examples
- Effective with few samples
- Continuous Loop: Improves from corrections
Receiver
Ingest documents from any channel or capture source.
- Multi-Source Intake: Email, scanners, APIs, mobile
- Realtime Capture: Streams documents as they arrive
- Embedded Metadata: Stores origin, timestamps, and system context
Tagger
Apply semantic and business metadata to documents.
- Contextual Tags: Entity, date, case, type
- Auto-Labelling: AI or rule-driven
- Retrieval Ready: Enhances search accuracy and routing
Developer
Add custom logic, scripts, and tools securely.
- Safe Sandbox: Execute JS/Python in isolation
- Custom Operators: Build nodes tailored to workflows
- Integrate seamlessly with all of your nodes.
Archiver
Store, index, and retrieve documents with full context.
- Vector Search: Retrieve documents semantically
- Metadata First: Structured indexing and lifecycle rules
- Immutable History: Maintains every version and change
Reviewer
Human-in-the-loop quality control and decision-making.
- Guided Review: Highlights conflicts and low-confidence fields
- Multi-Mode Approval: Accept, correct, or escalate
- Audit Safe: Logs decisions and reviewer identity
Composer
Generate outputs, summaries, or full documents dynamically.
- Template Fusion: Merge data into branded outputs
- AI Composition: Draft reports or letters
- Multi-Format: PDF, DOCX, email, or structured exports
Deliver Speed, Quality, and Adaptable Document Processing
Faster
Automate scanning, splitting, extraction, and routing to eliminate bottlenecks and accelerate processing across document-heavy operations.
Accurate
Domain-tuned models and Guard Railed Agents deliver reliable extraction, classification, and assembly with fewer errors and more consistent outputs.
Compliant
Detailed logs, retention controls, and governance features support strict regulatory, audit, and quality requirements.
Adaptive
Update flows, models, and business rules instantly, ensuring document processes evolve as requirements change.
Complete
Assemble documents into structured, consistent case files with predictable organization and rule-based completeness checks.
Insightful
Track confidence, throughput, routing performance, and operational metrics to continuously improve document workflows
Specialized Models for High Speed, Accurate and Offline Processing
Faster Execution — compact, optimized, instantaneous
Specialized models run at high speed on CPUs, enabling real-time processing without heavy infrastructure.
Higher Accuracy — consistent, precise, reliable
Domain-tuned models deliver superior extraction, classification, splitting and reasoning performance compared to generic LLMs.
Fully Offline — secure, compliant, self-contained
Models operate entirely offline for environments requiring strict data control and zero external dependencies.
One System, Zero Data Movement
Use one platform for processing and archival logic by storing vectors and metadata in Papyri while documents remain in their existing systems.
Eliminate costly duplication and data relocation by layering intelligence over your repositories without moving or restructuring the underlying documents.
Pay Only For What You Use
Stop paying for "user seats" or vague licensing fees. Papyri operates on a transparent, metric-driven model designed for scale.
Built for Mission-Critical Enterprise Scale
Enterprise-grade reliability, security, and governance ensure stable workflows across regulated industries.
-
✓Role-based access control
-
✓Multi-tenant isolation
-
✓Full audit trails
-
✓Seamless integrations
-
✓High scalability
-
✓Disaster Recovery
Ready to stop the waste?
Join the CIOs who are processing documents with the accuracy of Foundational Models and the speed of automation.
Request Enterprise Access