Instantly convert decades of degraded documents into clean, structured, and AI-ready assets without compromising their audit integrity.
Massive historical archives often contain poor-quality scans or complex, non-standard files, making them unusable for modern AI models and difficult to search.
Information is locked away in outdated ECMs and proprietary formats.
Faded text, bleed-through, and poor contrast hinder modern OCR and extraction.
No unified taxonomy or metadata across historical batches.
Inability to quickly locate records leads to slower compliance reporting and eDiscovery.
Historical data remains untapped for business intelligence and analytics.
Papyri revitalizes legacy archives by automatically cleaning degraded images, extracting hidden metadata, and creating a unified semantic index. This flow makes vast document stores immediately searchable, usable by downstream Agents, and compliant, all while preserving a verifiable audit trail of the original file.
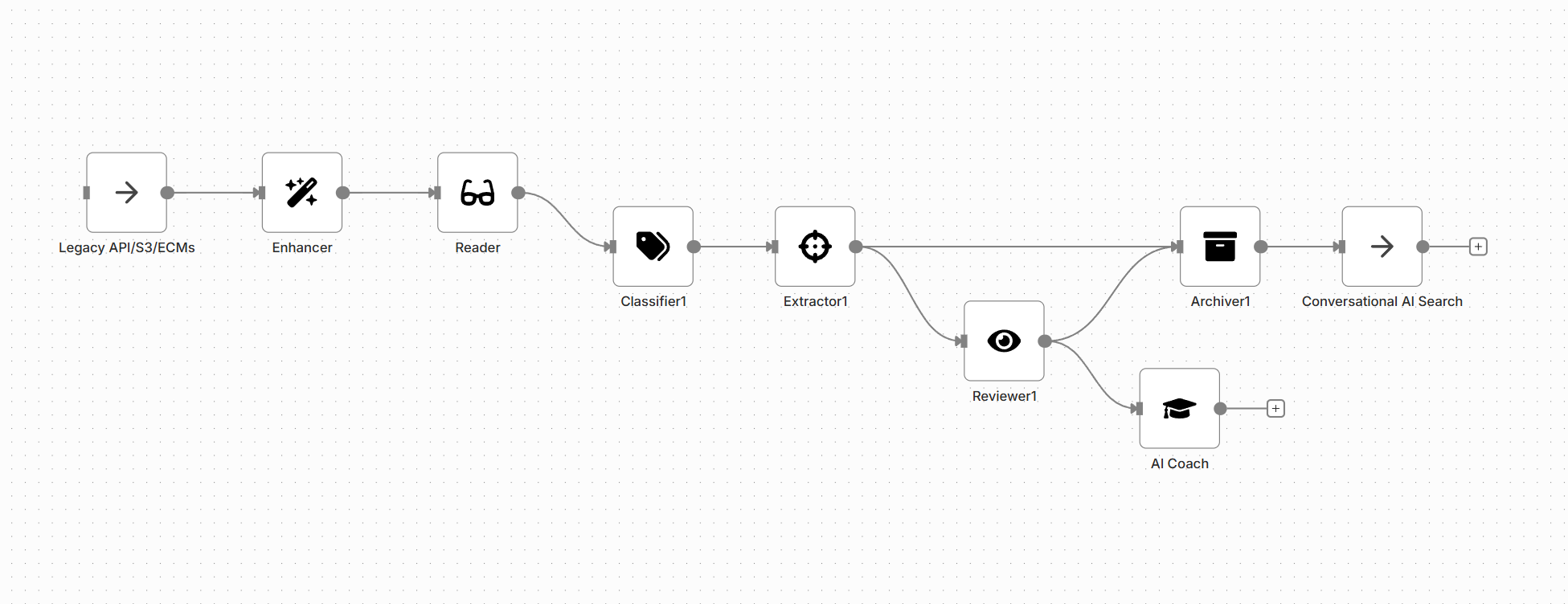
This workflow is designed to process massive backlogs efficiently, focusing on improving data quality before long-term storage and discovery.
| Papyri Node | Role in Solution |
|---|---|
| Receiver | Pulls documents from historical repositories (e.g., SharePoint, FileNet, S3). |
| Enhancer | Uses Generative AI to fix faded, crumpled, or degraded archive images for maximum readability. |
| Reader | Creates the Digital Twin, capturing complex layouts and text from non-standard archive documents. |
| Classifier | Assigns a modern, unified taxonomy to historical documents for consistency. |
| Extractor | Retrieves key historical metadata that was previously missing (e.g., legacy ID numbers, dates). |
| Archiver | Stores the document, its metadata, and its vector embeddings for conversational search. |
| Reviewer | Validates the accuracy of historical data extraction and classification samples. |
Search through historical data using natural language queries over the vector index.
Immediately locate records for audits and regulatory requests.
De-duplication and smart archiving reduce physical and digital storage footprint.
High-quality, clean historical data fuels downstream machine learning initiatives.
Archives Modernization is essential for organizations with significant historical document liabilities and data trapped in legacy systems.
Ensures cryptographic hash validation throughout the restoration process, preserving the original file's authenticity.
Maintains contextual indexing and searchability regardless of whether the physical files reside on-prem or in the cloud.
Supports legal hold and audit logs during the transfer and restoration phases.
Capable of handling petabyte-scale archives and running continuous indexing jobs without performance degradation.
Connects directly to legacy ECMs (e.g., Documentum, FileNet) and cloud storage APIs (S3, Azure Blob).
Provides detailed metrics on data quality improvement and restoration success rates per batch.