Instantly query your entire document repository using natural language, revealing hidden trends and insights across vast, unstructured data.
Traditional keyword search is ineffective for complex queries (e.g., "Show me all contracts with penalty clauses over $10k from clients in Texas"). Discovering trends across thousands of documents is impossible.
Cannot search for conceptual or semantic meaning, only exact matches.
Employees spend hours manually digging through files to answer complex questions.
Strategic data (market trends, risks) remains buried in unstructured text.
Only structured data is available for business intelligence (BI) tools.
This flow leverages the Archiver's vector indexing capability to enable semantic search. The Agent acts as the conversational interface, accepting a natural language query, retrieving relevant document snippets from the Archiver, and synthesizing a precise, grounded answer, ready for direct analysis.
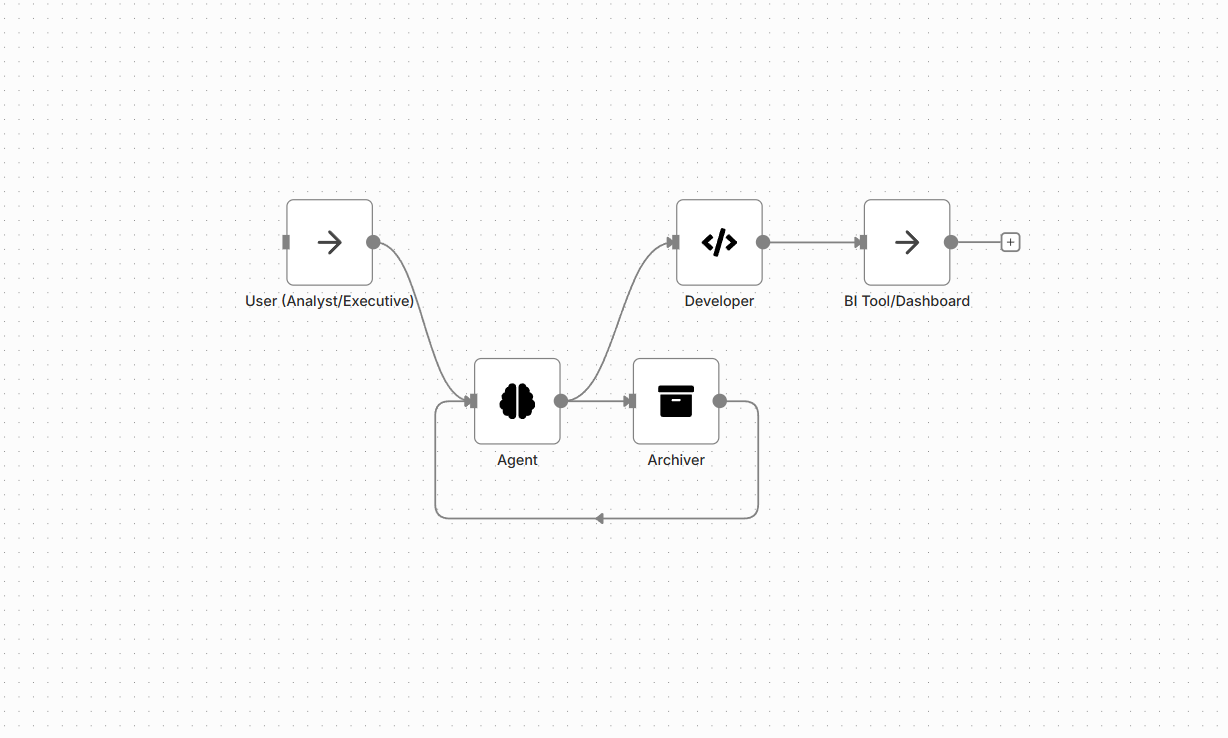
The focus is on using the Agent to bridge the gap between unstructured document data and structured analytical needs.
| Papyri Node | Role in Solution |
|---|---|
| Archiver | Indexes all documents using vector embeddings and metadata, providing the knowledge base. |
| Agent | The core intelligence. Translates the user's natural language into a search query, retrieves results, and synthesizes a final answer. |
| Developer | Provides tools for the Agent to push the synthesized results into external analytical tools (e.g., Tableau, Power BI). |
Get complex, cross-document answers in seconds instead of hours.
Discover hidden trends (e.g., common legal risks, market shifts) previously locked in text.
Everyone can access document intelligence without needing specialized data science skills.
Unstructured document content is now usable by mainstream BI platforms.
This flow unlocks the strategic value of all recorded document history.
The Archiver automatically converts content into vector embeddings, enabling conceptually relevant search results, not just keyword matches.
Optimized for speed, ensuring the Agent can retrieve relevant document snippets for conversational queries in milliseconds.
All searches and Agent responses are logged, ensuring a clear audit trail of what information was accessed and when.
The Archiver's index layer scales independently from the physical storage, supporting massive growth in document volume without performance hit.
Enforces strict role-based access for search results, ensuring users only retrieve documents they are authorized to view.
Tracks query volume, search accuracy, and common information gaps in the archive.