Proactively scan your existing document repository to find and fix errors, duplicates, and metadata gaps for a perfectly clean archive.
Archives naturally degrade due to human error, system migrations, and a lack of enforcement, resulting in low search accuracy and poor compliance.
Inconsistent naming and system errors result in multiple copies of the same document.
Documents are missing key indexing fields (e.g., Customer ID, Date).
Human error leads to documents being tagged with misspelled or non-standard category names.
Bad data makes retrieval and analysis unreliable.
The flow uses Receiver to ingest the existing archive's index, then uses Agent and Extractor to perform a data integrity audit. It identifies duplicates, flags missing metadata, and uses the Tagger to enforce correct, standardized values across the entire repository. This proactive cleanup ensures the archive remains a reliable, searchable source of truth.
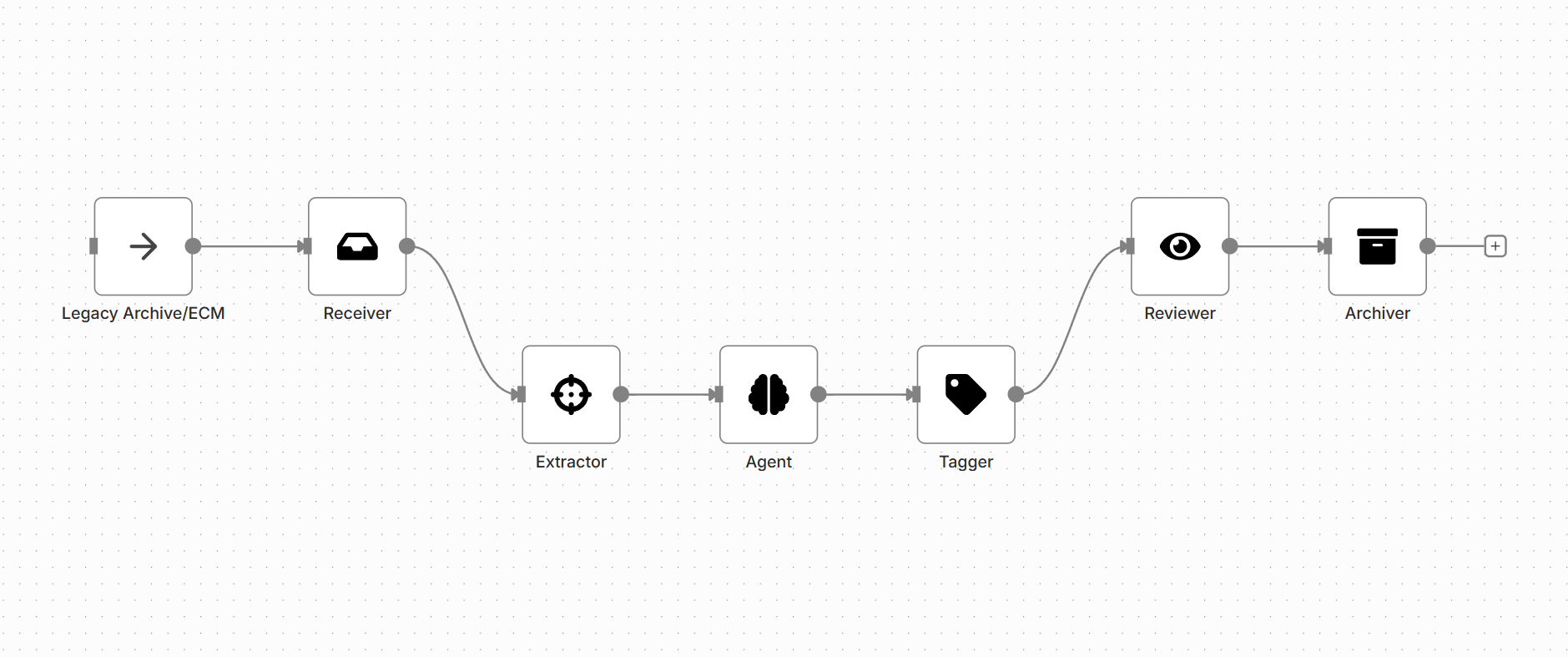
This process is designed for a large-scale, one-time or scheduled audit of an existing document repository's data fidelity.
| Papyri Node | Role in Solution |
|---|---|
| Receiver | Connects to and pulls the document index and metadata from the legacy/target archive. |
| Extractor | Pulls all existing metadata fields for audit and finds missing fields by reading the document content. |
| Agent | The audit brain. Compares documents to find duplicates, validates metadata formats, and flags inconsistencies. |
| Tagger | Applies corrected, standardized metadata values and ensures a unified taxonomy is enforced. |
| Reviewer | A human expert validates the Agent's proposed fixes (e.g., "Yes, this is a duplicate of ID X"). |
| Archiver | Stores the final, corrected metadata layer, ensuring high search accuracy. |
Ensures all searches (both AI and keyword) return accurate, relevant results.
Eliminates costly duplicate files from the repository.
Standardized metadata improves downstream reporting and analytics.
Closes metadata gaps that could lead to non-compliance issues.
This flow is a crucial maintenance function for any organization that treats its archive as a business asset.
All metadata fixes and deduplication flags are applied to the Archiver's index layer first, ensuring the original archive documents remain untouched.
Creates an audit trail detailing every metadata correction made, including the old value, the new value, and the approving Reviewer.
The Agent uses advanced algorithms (e.g., vector similarity) to reliably detect conceptual duplicates, not just filename matches.
Optimized for running intensive, full-archive audit sweeps over massive backlogs without impacting daily operational workflows.
Correction actions require role-based Reviewer approval, preventing unauthorized or accidental changes to critical archive data.
Dashboards clearly show "dirty data" metrics: the volume of duplicates found, metadata field completeness, and overall archive health over time.