Automated batch splitting, classification, and metadata extraction at scale
As scan volumes grow, human processing becomes the bottleneck—slowing operations and increasing error rates.
Human operators can’t keep up with scanner speeds.
Manual classification and entry introduce inconsistencies.
Labor scales linearly with volume, inflating cost per document.
Papyri transforms high-volume scanning into a fully intelligent workflow that eliminates manual intervention. By combining advanced document intelligence with Agentic AI, we automatically handle everything from batch splitting to metadata extraction.
The result? Clean, searchable, compliant digital assets delivered at unmatched speed and accuracy—turning raw scanned pages into structured enterprise knowledge instantly.
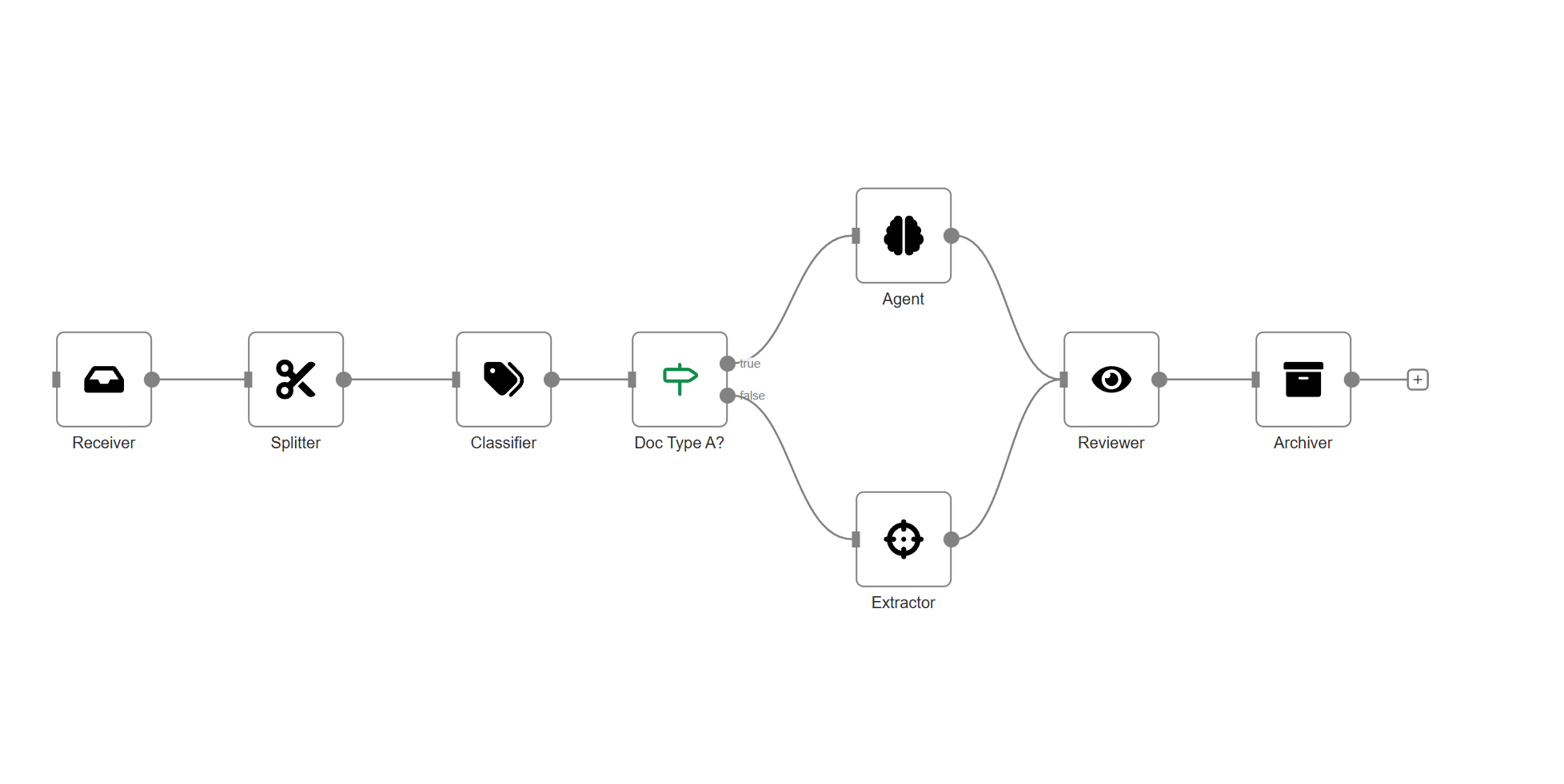
Papyri orchestrates specialized AI nodes to deliver end-to-end intelligent capture
| Papyri Node | Role in Solution |
|---|---|
| Intake Gateway | Receives scanned batches from scanners or directories with automatic normalization |
| Smart Tagger | Adds unique document IDs for complete traceability and audit compliance |
| Batch Splitter | Automatically splits mixed multi-page batches into individual documents |
| Document Intelligence Engine | Performs OCR, layout analysis, and structure extraction to create document twins |
| Business Taxonomy Engine | Classifies document types and extracts critical metadata with high accuracy |
| Router | Routes exceptions and handles errors intelligently based on confidence scores |
| Integration Connectors | Delivers documents and metadata to destination systems following defined hierarchies |
| Knowledge Vault | Stores enriched content with semantic search capabilities across all processed documents |
| Human Review Console | Enables efficient review of exceptions only when AI confidence is low |
| AI Learning Engine | Continuously improves models using reviewer feedback and validation data |
Eliminate manual sorting and indexing bottlenecks with AI-powered automation that matches scanning speeds
Free your team from repetitive document processing tasks to focus on high-value activities
AI plus business rules deliver consistent, validated metadata with minimal human review needed
Semantic search across all processed content with properly structured metadata and folder hierarchies
Complete traceability with versioning, validation logs, and audit-ready documentation
Enforce naming conventions and folder standards automatically across all document repositories
Organizations across industries rely on Papyri to transform their document capture operations
Connects to SharePoint, Alfresco, OpenText, FileNet, Laserfiche, S3, Azure Blob, and more via API-first design
Built to meet regulatory requirements with full audit trails, versioning, and data governance controls
Deploy on cloud, on-premises, or hybrid infrastructure based on your security and compliance needs